
When people talk about artificial intelligence, they usually focus on the model. They debate whether ChatGPT Gemini comparisons are fair, ask whether DeepSeek vs ChatGPT performance is stronger, or argue about llm benchmarks and llm parameter size comparison. Very few conversations begin with the more important question: what data does AI use to become intelligent in the first place?
The answer is data annotation.
If you search for what data annotation is, you are not just looking for a definition. You are looking for a mechanism that allows learning systems in artificial intelligence to move from theory to a usable product. Data annotation is the structured labeling of raw information so that machine learning algorithms can detect patterns, validate predictions, and refine their outputs. Without annotation, even the most advanced machine learning algorithms or transformer AI models remain blind to meaning.
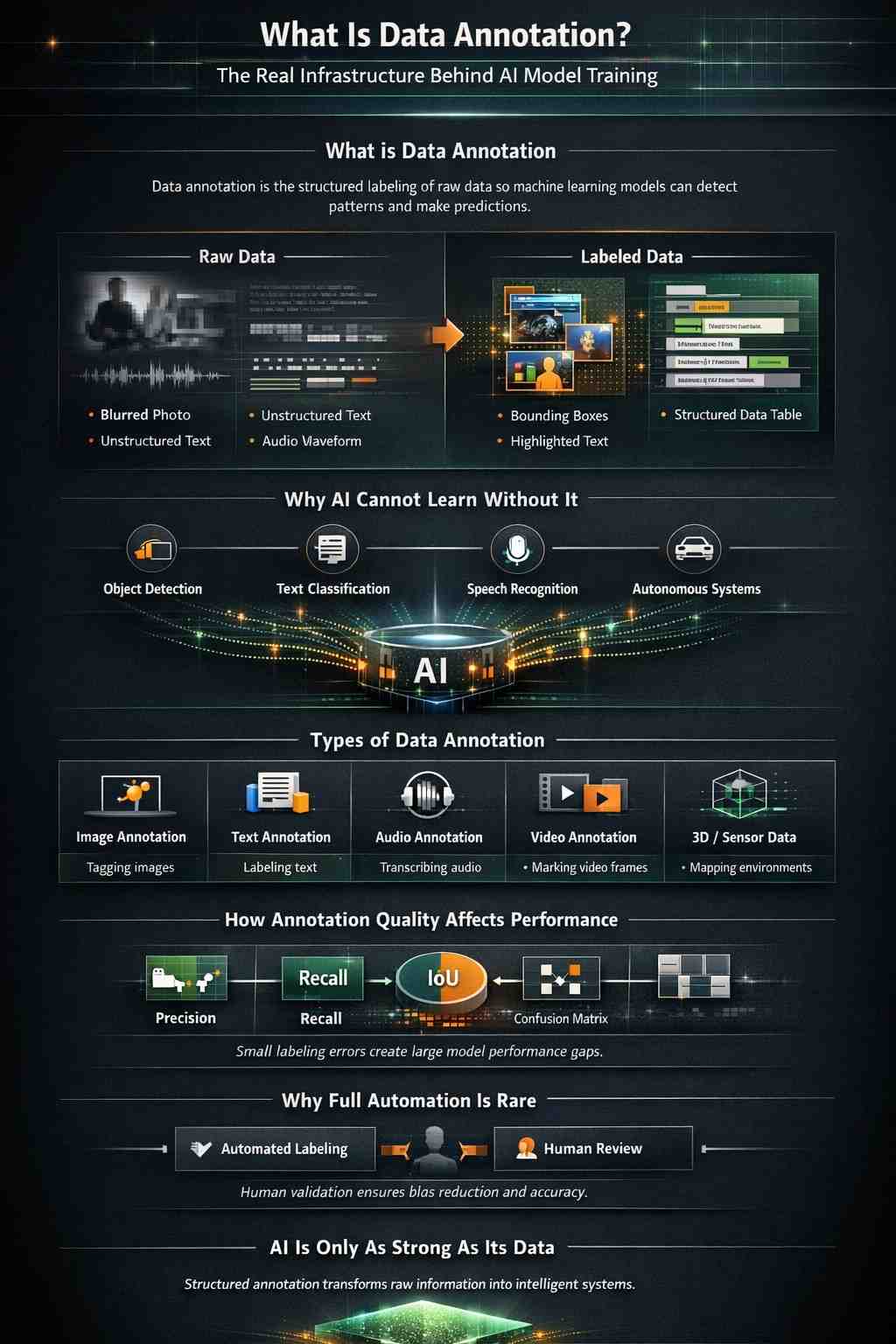
Artificial intelligence does not “see” an image the way humans do. When people ask how AI recognizes images or how AI models are trained, the explanation always leads back to structured datasets. A dataset is more than a collection of files. It is an organized body of labeled examples that allows a model to distinguish patterns, detect relationships, and optimize predictions. This information used in machine learning forms the training ground for systems that perform document classification, machine learning text recognition, or even autonomous car machine learning.
Consider a simple example in computer vision. If you want asystem capable of image recognition and artificial intelligence, it must be exposed to thousands, sometimes millions, of labeled examples. Those examples might come from a facial dataset, a face recognition dataset, or a dataset for facial recognition that distinguishes identity markers across lighting conditions. Each image must be tagged with precise labels so the model can learn. That tagging process is image annotation. When the labeling becomes more complex, such as identifying objects within an image, it may require bounding box placement, polygon annotations, or full semantic segmentation across pixels.
This is where data annotation software and data annotation tools become critical. Modern AI SaaS companies rely on astructured data annotation platform or an annotation platform that manages workflow, quality control, and versioning. An effective image annotation tool must allow teams to label their data efficiently while tracking inter-annotator agreement to ensure consistency. When multiple annotators review the same dataset, disagreement metrics reveal whether annotation guideline standards are clear or ambiguous.
The quality of annotation directly influences evaluation metrics. If you measure performance using a confusion matrix or multiple confusion matrices across validation dataset splits, errors often trace back to labeling inconsistencies rather than algorithm weakness. Teams calculating intersection over union scores or learning how to compute Map quickly realize that small annotation errors can distort object detection metric results. In applications involving object detection vs image classification, precise labeling becomes the difference between aproduction-ready model and a research prototype.
Text-based AI systems require a similar foundation. Text annotation services and text annotation service pipelines support intent classification, language annotation, and text classification datasets used in supervised vs unsupervised learning experiments. If you are building systems that relyon machine learning document classification or automated customer support, your text dataset must be curated carefully. Even resume datasets used in HR automation require structured tagging so that the algorithm and machine learning workflow align correctly.
Audio annotation service processes introduce another layer of complexity. Voice bot training requires labeled audio clips that identify speech segments, emotional tone, and contextual meaning. When organizations build multimodal dataset environments combining text, image, and audio, annotation becomes even more intricate. Advanced projects involving 3D lidar point cloud mapping or visual simultaneous localization and mapping systems demand precise labeling standards across spatial dimensions.
Data sparsity's meaning becomes important here. Data sparsity occurs when the dataset lacks sufficient representation of certain edge cases. Sparsity data issues frequently cause performance degradation in long tail scenarios. To mitigate this, teams apply data augmentation or develop synthetic datasets and synthetic data approaches to strengthen coverage. Resources such as the UCI machine learning repository, UC Irvine datasets, or UCI ML repository collections provide baseline experimentation material, but commercial AI products typically demand proprietary datasets aligned to specific objectives.
As AI systems grow more advanced, questions about LLM meaning, LLM means, LLM abbreviation, and what does llm stand for emerge inparallel with discussions about strong AI and weak AI. Whether analyzing DeepSeek vs ChatGPT benchmarks, ChatGPT vs DeepSeek comparison, or comparing types of llm models and llm types, the same principle applies. Every large language model depends on structured training data derived from common crawl sources, curated text dataset archives, and annotated corpora refined through AI training methods.
Even specialized domains such as artificial intelligence inagriculture, AI farming, crop monitoring, drone analysis, or machine learning driverless cars rely on accurate segmentation datasets and driving dataset annotation. Systems built for object detection in OpenCV Python or object detection in OpenCV applications require structured labeling before deployment. In medical contexts, medical data annotation supports diagnostic systems that classify patterns invisible to the human eye.
Behind all of this lies storage architecture. Understanding components of a database management system and what are the main components of a database system becomes critical when scaling annotation pipelines. Organizations often explore database annotation and components of database system structures to ensure version control and traceability. When engineers ask what the components of a database management system are or what the components of a database system are, they are indirectly addressing the scalabilityof annotation infrastructure.
Ultimately, data annotation is not a peripheral service. It is the foundation of AI learning system design. It connects raw data to algorithm execution. It enables pattern recognition and machine learning optimization. It transforms unstructured information into actionable intelligence.
If you strip away the headlines about scale.ai pricing, scale ai data labeling, scale ai competitors, or discussions about what is scale ai and what does scale ai do, you return to a simple truth. AI performance is only as strong as the dataset behind it. And a dataset is onlyas reliable as the annotation process that shaped it.
That is why data annotation services, data labeling services, and machine learning labeling workflows are not optional add-ons. They are the structural backbone of modern AI SaaS products. Whether you are building semantic segmentation systems, developing face identification dataset pipelines, experimenting with machine learning repository UCI samples, or comparing Gemini vs ChatGPT 4 performance, your competitive advantage begins with how well your data is labeled.
Artificial intelligence may appear autonomous. It is built on human-guided annotation that gives structure to information. Without that foundation, even the most advanced AI terminator fantasies remain science fiction. With it, AI systems move from experimentation to enterprise-scale deployment.
Trust TRANSFORM Solutions to be your partner in operational transformation.
Trust TransForm Solutions to be your partner in operational transformation.
